Road surface temperature prediction with random forests
Continuing with the different algorithms I proposed to use in in a previous post, I will now use a random forest algorithm to calculate road temperature at unknown points.
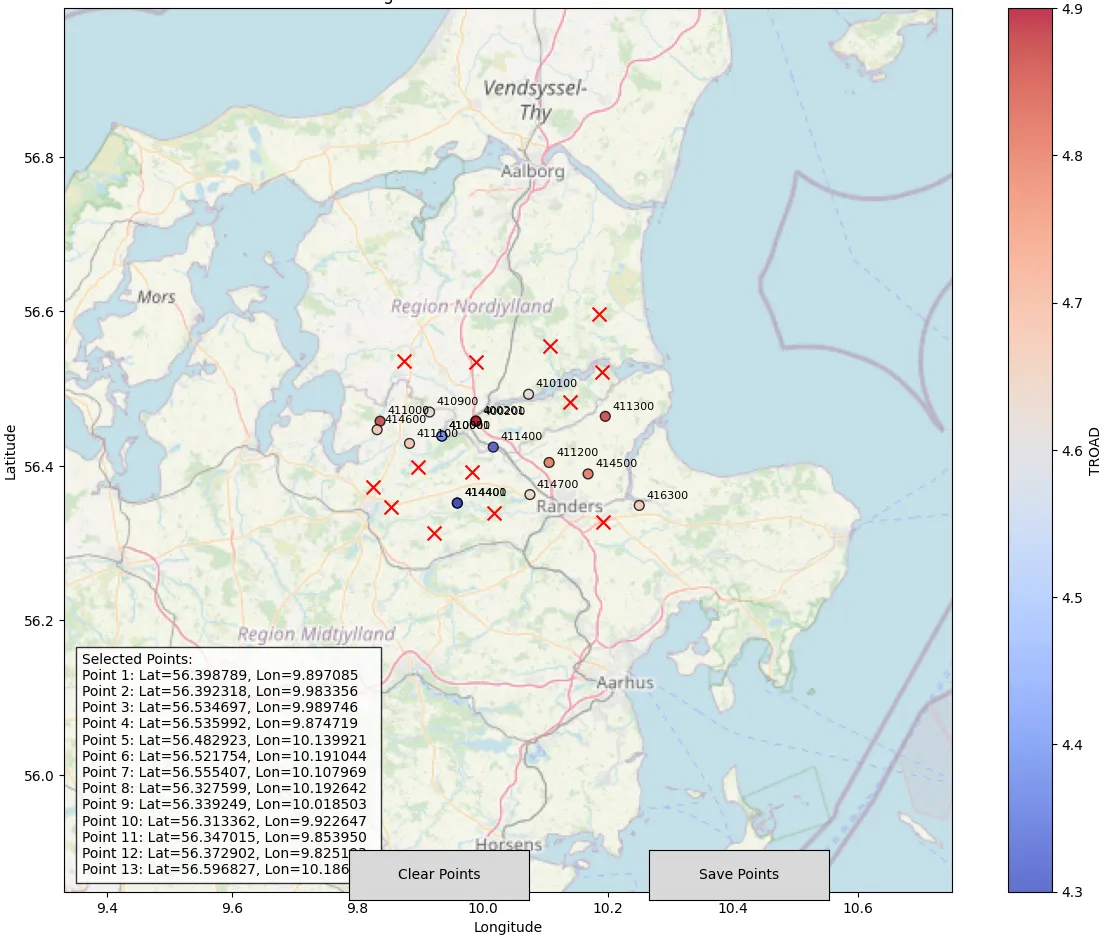
To recap, we are interested in the same problem described in the kriging method: predicting the temperatures at the points marked by Xs in the figure below.
Random forests are an example of an ensemble method in machine learning. An ensemble combines multiple individual learning models to produce an aggregate model that is more powerful than any of its individual components. Random forests apply this ensemble idea to decision trees. Decision trees are a supervised learning method that can be used for both regression and classification. They are especially useful when you want to understand which features are most influential in a dataset. Decision trees learn a series of explicit if-then rules on feature values that result in a decision predicting the target value.
Decision trees are a good alternative for estimating temperatures using information about the terrain, because temperature has some clear relationships with terrain, such as:
- High elevation → colder (though not always linear)
- North-facing slopes → colder in winter, cooler in summer
- Valley bottoms → temperature inversions
- Coastal vs inland effects
With this rationale we can create some spatial features to be used by the random forest algorithm.
Features selection
We can think of two simple types of features based on the station locations and the terrain characteristics: distance-based features and terrain features.
- Distance-based features:
The minimum distance and mean distance to the nearest N neighbours can capture spatial autocorrelation - nearby locations have similar temperatures. Stations closer to others benefit from "neighborhood information" using lon, lat of station. Location can also account for geographic gradients (latitude affects solar radiation). Based on this we can define three distance based features:
- min_distance: Minimum distance to nearest weather station
- mean_distance_Nnn: Average distance to N nearest neighbours (we will choose 5 neighbours in this example).
- lon_lat_interaction: accounts for regional climate patterns that depend on both coordinates and helps model complex spatial relationships. The lat and lon needs to be normalized to prevent coordinate scale issues.
- Terrain Features: These features will be based on the terrain characteristics provided by the elev_m,slope_deg and aspect_deg calculated for the Kriging method. Combinations of these features can be used to include some linear and non-linear interactions. For example steep slopes at high elevations have different thermal behavior. Squaring some terms can account for non-linear elevation/slope effects on temperature. From this we can derive 3 different features:
- elev_slope_interaction: Elevation × slope interaction
- elev_squared, slope_squared: Non-linear terrain effects
- aspect_sin, aspect_cos: Cyclical aspect representation
Note that the features above are by no means the only available choices, but were chosen here for convenience to illustrate the random forest algorithm.
The code below takes the distance and terrain features into account and creates the relevant forest regressor model using sklearn.
"""
Random Forest Road Temperature Prediction
"""
import os
import sqlite3
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.spatial.distance import cdist
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
class RoadTemperatureRF:
"""Random Forest model for road temperature prediction using only predictable features"""
def __init__(self, random_state=42):
self.rf_model = None
self.scaler = StandardScaler()
self.feature_names = None
self.random_state = random_state
self.feature_importance_ = None
def load_and_merge_data_optimized(self, variables, year, db_path="./OBSTABLE"):
"""Load data from SQLite databases and merge into a single dataframe."""
dataframes = []
for variable in variables:
db_file = os.path.join(db_path, f'OBSTABLE_{variable}_{year}.sqlite')
if not os.path.exists(db_file):
print(f"Warning: Database file not found: {db_file}")
continue
conn = sqlite3.connect(db_file)
conn.execute('PRAGMA synchronous = OFF')
conn.execute('PRAGMA journal_mode = MEMORY')
query = f"SELECT valid_dttm, SID, lat, lon, {variable} FROM SYNOP"
try:
for chunk in pd.read_sql_query(query, conn, chunksize=10000):
dataframes.append(chunk)
except sqlite3.Error as e:
print(f"SQLite error when reading {variable}: {e}")
finally:
conn.close()
if not dataframes:
raise ValueError("No data loaded from database")
full_df = pd.concat(dataframes, ignore_index=True)
merged_df = full_df.groupby(['valid_dttm', 'SID', 'lat', 'lon']).first().reset_index()
return merged_df
def create_spatial_features(self, df):
"""Create spatial features for capturing spatial autocorrelation"""
coords = df[['lon', 'lat']].values
if len(coords) > 1:
distances = cdist(coords, coords)
np.fill_diagonal(distances, np.inf)
df['min_distance'] = np.min(distances, axis=1)
if len(coords) >= 5:
sorted_distances = np.sort(distances, axis=1)
df['mean_distance_5nn'] = np.mean(sorted_distances[:, :5], axis=1)
else:
df['mean_distance_5nn'] = df['min_distance']
else:
df['min_distance'] = 0
df['mean_distance_5nn'] = 0
# Normalized spatial coordinates
df['lon_norm'] = (df['lon'] - df['lon'].mean()) / df['lon'].std() if df['lon'].std() > 0 else 0
df['lat_norm'] = (df['lat'] - df['lat'].mean()) / df['lat'].std() if df['lat'].std() > 0 else 0
df['lon_lat_interaction'] = df['lon_norm'] * df['lat_norm']
return df
def create_terrain_interactions(self, df):
"""Create interaction features between terrain variables"""
if 'elev_m' in df.columns and 'slope_deg' in df.columns:
df['elev_slope_interaction'] = df['elev_m'] * df['slope_deg']
if 'elev_m' in df.columns:
df['elev_squared'] = df['elev_m'] ** 2
if 'slope_deg' in df.columns:
df['slope_squared'] = df['slope_deg'] ** 2
if 'aspect_deg' in df.columns:
aspect_rad = np.deg2rad(df['aspect_deg'])
df['aspect_sin'] = np.sin(aspect_rad)
df['aspect_cos'] = np.cos(aspect_rad)
return df
def prepare_features(self, df):
"""Prepare feature matrix - EXCLUDING meteorological observations since we do not know them"""
df = self.create_spatial_features(df)
#df = self.create_temporal_features(df)
df = self.create_terrain_interactions(df)
# Define feature groups - NO METEOROLOGICAL OBSERVATIONS
base_features = ['lon', 'lat']
# Terrain features (available for both training and prediction)
terrain_features = []
for col in ['elev_m', 'slope_deg', 'aspect_deg', 'elev_slope_interaction',
'elev_squared', 'slope_squared', 'aspect_sin', 'aspect_cos']:
if col in df.columns:
terrain_features.append(col)
# Spatial features (can be computed for any location)
spatial_features = ['lon_norm', 'lat_norm', 'lon_lat_interaction',
'min_distance', 'mean_distance_5nn']
# Combine all PREDICTABLE features
self.feature_names = (base_features + terrain_features +
spatial_features) # + temporal_features)
# Filter to only include available columns
available_features = [col for col in self.feature_names if col in df.columns]
self.feature_names = available_features
print(f"Using {len(self.feature_names)} features: {self.feature_names}")
return df[self.feature_names]
...
The whole code can be found in this github repository, where I integrated some of the functions used in the kriging algorithm.
Comparison with the kriging algorithm
Now we test the random forest (RF) prediction with the Kriging method from the previous post on the winter and summer dates.
The predictions of both methods are quite close. For example, for the first 6 points the results are highlighted below.

For the point represented by station "999901" the RF algorithm gives 26.71, while Kriging gives 26.29. For the point represented by station "999905" the differences are larger with RF predicting 27.67 deg while Kriging gives 25.35. However, the RF forest uncertainty is smaller (3 deg instead of 5). An statistical summary of the results for all stations is shown below.
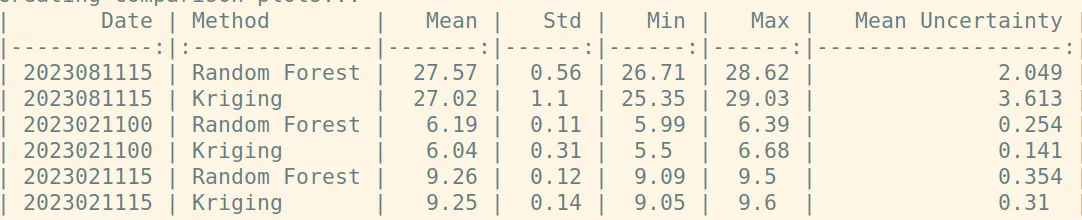 Comparison by date:
Comparison by date:
2023081115:
- RF mean: 27.57°C, Kriging mean: 27.02°C
- Mean difference: 0.538°C
- RMSE: 0.982°C
2023021100:
- RF mean: 6.19°C, Kriging mean: 6.04°C
- Mean difference: 0.153°C
- RMSE: 0.295°C
2023021115:
- RF mean: 9.26°C, Kriging mean: 9.25°C
- Mean difference: -0.014°C
- RMSE: 0.104°C
Uncertainty comparison:
- RF mean uncertainty: 0.8859
- Kriging mean uncertainty: 1.3548
Final comments
In summary, the random forest algorithm provides a viable alternative to kriging for predicting road temperatures, with comparable accuracy and potentially lower uncertainty in some cases. While both methods show similar mean predictions, the random forest approach offers a different perspective on feature importance and spatial relationships.
While the random forest algorithm shows promise for road temperature prediction, there are still many avenues for improvement. Future work could focus on incorporating more sophisticated feature engineering, such as temporal features or weather forecast data. Additionally, a more comprehensive comparison with other machine learning techniques and spatial interpolation methods would provide valuable insights into the strengths and weaknesses of each approach.