Fetching weather data from a popular weather app
One of the most popular and accurate weather apps in my area is the YR weather app, a product of the Norwegian Meteorological Institute (MET Norway for short). What sets this app apart is that its forecasts are updated very frequently and post-processed using data from local weather stations.
In line with MET Norway's open-source policy for software and data, there is a very detailed github page describing how to download data from this app. The data is accessible through their Threads service OPeNDAP (Open-source Project for a Network Data Access Protocol), a data access protocol that facilitates the sharing of scientific datasets. THREDDS (Thematic Real-time Environmental Distributed Data Services) is a server that provides access to scientific datasets, often using OPeNDAP and other protocols.
I want to use the predictions from YR to provide an example of the kind of standard point verification we carry out at work to evaluate model performance. By point verification I mean I am interested in evaluating the point predictions of the model (something that is sometimes unfair to the more high resolution model, as I explained in a previous post) The question I want to answer here is: How good is YR’s current prediction for the next two weeks at one of the beaches near where I live? I’m interested in temperature and wind (ignoring rain for now) to decide if it’s going to be beach weather or not.
Following the examples in this link, I will use python to download and parse the data for a particular, using the standard SYNOP variables 2m temperature (T2m) and wind speed at 10 m (S10m) provided by YR.
Downloading the data, I will save it in a sqlite format with some specific formatting for later use.
import sqlite3
import pandas as pd
from datetime import datetime, timezone
import json
def download_weather_data_and_create_sqlite():
# Coordinates for Sandskogen beach, Ystad, Sweden
lat = 55.4295
lon = 13.8200
# Open-Meteo API endpoint for forecast data
url = "https://api.open-meteo.com/v1/forecast"
# Parameters for the API request
params = {
'latitude': lat,
'longitude': lon,
'hourly': ['temperature_2m', 'wind_speed_10m'],
'forecast_days': 16, # Get 30 days of forecast
'timezone': 'Europe/Stockholm'
}
print(f"Downloading weather data for Sandskogen beach, Ystad, Sweden")
print(f"Coordinates: {lat}°N, {lon}°E")
# Make the API request
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print("✓ Data downloaded successfully")
# Extract relevant information
hourly_data = data['hourly']
times = hourly_data['time']
temperatures = hourly_data['temperature_2m']
wind_speeds = hourly_data['wind_speed_10m']
# Get current date for filename (YYYYMM format)
current_date = datetime.now()
month_str = current_date.strftime('%Y%m')
# Create filenames for each variable
temp_filename = f"FCTABLE_T2m_{month_str}_00.sqlite"
wind_filename = f"FCTABLE_S10m_{month_str}_00.sqlite"
# Get forecast initialization time (current time in unix)
fcst_dttm = int(datetime.now(timezone.utc).timestamp())
# Function to create table and insert data
def create_and_populate_db(filename, parameter_data, parameter_name, units, sid):
conn = sqlite3.connect(filename)
cursor = conn.cursor()
# Create the table with the specified schema
cursor.execute('''
CREATE TABLE IF NOT EXISTS "FC" (
"SID" INTEGER,
"valid_dttm" INTEGER,
"lead_time" INTEGER,
"YR_det" REAL,
"p" REAL,
"lon" REAL,
"lat" REAL,
"model_elevation" REAL,
"fcst_dttm" INTEGER,
"parameter" TEXT,
"units" TEXT
)
''')
# Insert data
records_inserted = 0
for i, (time_str, value) in enumerate(zip(times, parameter_data)):
if value is not None: # Skip null values
# Convert time string to unix timestamp
dt = datetime.fromisoformat(time_str.replace('Z', '+00:00'))
valid_dttm = int(dt.timestamp())
# Calculate lead time in hours
lead_time = i
cursor.execute('''
INSERT INTO FC (SID, valid_dttm, lead_time, YR_det, p, lon, lat,
model_elevation, fcst_dttm, parameter, units)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
sid, # SID (station ID)
valid_dttm,
lead_time,
value, # YR_det (forecast value)
None, # p (pressure, not available)
lon,
lat,
data.get('elevation', 0), # model_elevation
fcst_dttm,
parameter_name,
units
))
records_inserted += 1
# Commit and close
conn.commit()
# Verify the data
cursor.execute("SELECT COUNT(*) FROM FC")
total_records = cursor.fetchone()[0]
# Show sample data
cursor.execute("""
SELECT SID, datetime(valid_dttm, 'unixepoch') as valid_time,
lead_time, YR_det, parameter, units
FROM FC
LIMIT 5
""")
sample_data = cursor.fetchall()
conn.close()
return total_records, sample_data
# Create temperature database
print(f"\n Creating temperature database: {temp_filename}")
temp_records, temp_sample = create_and_populate_db(
temp_filename, temperatures, 'T2m', '°C', 1
)
print(f"Temperature records inserted: {temp_records}")
print("Sample temperature data:")
print("SID | Valid Time | Lead | Value | Parameter | Units")
print("-" * 70)
for row in temp_sample:
print(f"{row[0]:3} | {row[1]:19} | {row[2]:4} | {row[3]:5.1f} | {row[4]:14} | {row[5]}")
# Create wind speed database
print(f"\n Creating wind speed database: {wind_filename}")
wind_records, wind_sample = create_and_populate_db(
wind_filename, wind_speeds, 'S10m', 'm/s', 2
)
print(f"Wind speed records inserted: {wind_records}")
print("Sample wind speed data:")
print("SID | Valid Time | Lead | Value | Parameter | Units")
print("-" * 70)
for row in wind_sample:
print(f"{row[0]:3} | {row[1]:19} | {row[2]:4} | {row[3]:5.1f} | {row[4]:14} | {row[5]}")
return temp_filename, wind_filename
else:
print(f"Error downloading data: {response.status_code}")
print(response.text)
return None, None
# Execute the function
temp_file, wind_file = download_weather_data_and_create_sqlite()
con=sqlite3.connect("FCTABLE_T2m_202506_00.sqlite")
df = pd.read_sql_query("SELECT * FROM FC",con)
print(df)
Now we use the code snippet below to plot the two variables and check for a beach worthy day in the next couple of weeks.
import pandas as pd
import sqlite3
from datetime import datetime
import requests
# Read temperature and wind data
df_temp = pd.read_sql_query(
"SELECT valid_dttm, YR_det FROM FC ORDER BY valid_dttm",
sqlite3.connect('FCTABLE_T2m_202506_00.sqlite')
)
df_temp['datetime'] = pd.to_datetime(df_temp['valid_dttm'], unit='s')
df_wind = pd.read_sql_query(
"SELECT valid_dttm, YR_det FROM FC ORDER BY valid_dttm",
sqlite3.connect('FCTABLE_S10m_202506_00.sqlite')
)
df_wind['datetime'] = pd.to_datetime(df_wind['valid_dttm'], unit='s')
# Merge on datetime
merged = pd.merge(df_temp, df_wind, on='datetime', suffixes=('_temp', '_wind'))
# Criteria for nice weather
NICE_TEMP = 20 # °C
NICE_WIND = 6 # m/s
nice = merged[(merged['YR_det_temp'] >= NICE_TEMP) & (merged['YR_det_wind'] <= NICE_WIND)].copy()
nice['is_weekend'] = nice['datetime'].dt.dayofweek >= 5 # 5=Saturday, 6=Sunday
# Prepare for precipitation download
nice_times = nice['datetime'].dt.strftime('%Y-%m-%dT%H:%M').tolist()
nice_times_str = ','.join(nice_times)
# Output the nice weather times and if they are on a weekend
nice_points = nice[['datetime', 'YR_det_temp', 'YR_det_wind', 'is_weekend']]
nice_points.reset_index(drop=True, inplace=True)
nice_points['datetime'] = nice_points['datetime'].dt.strftime('%Y-%m-%d %H:%M')
print(nice_points)
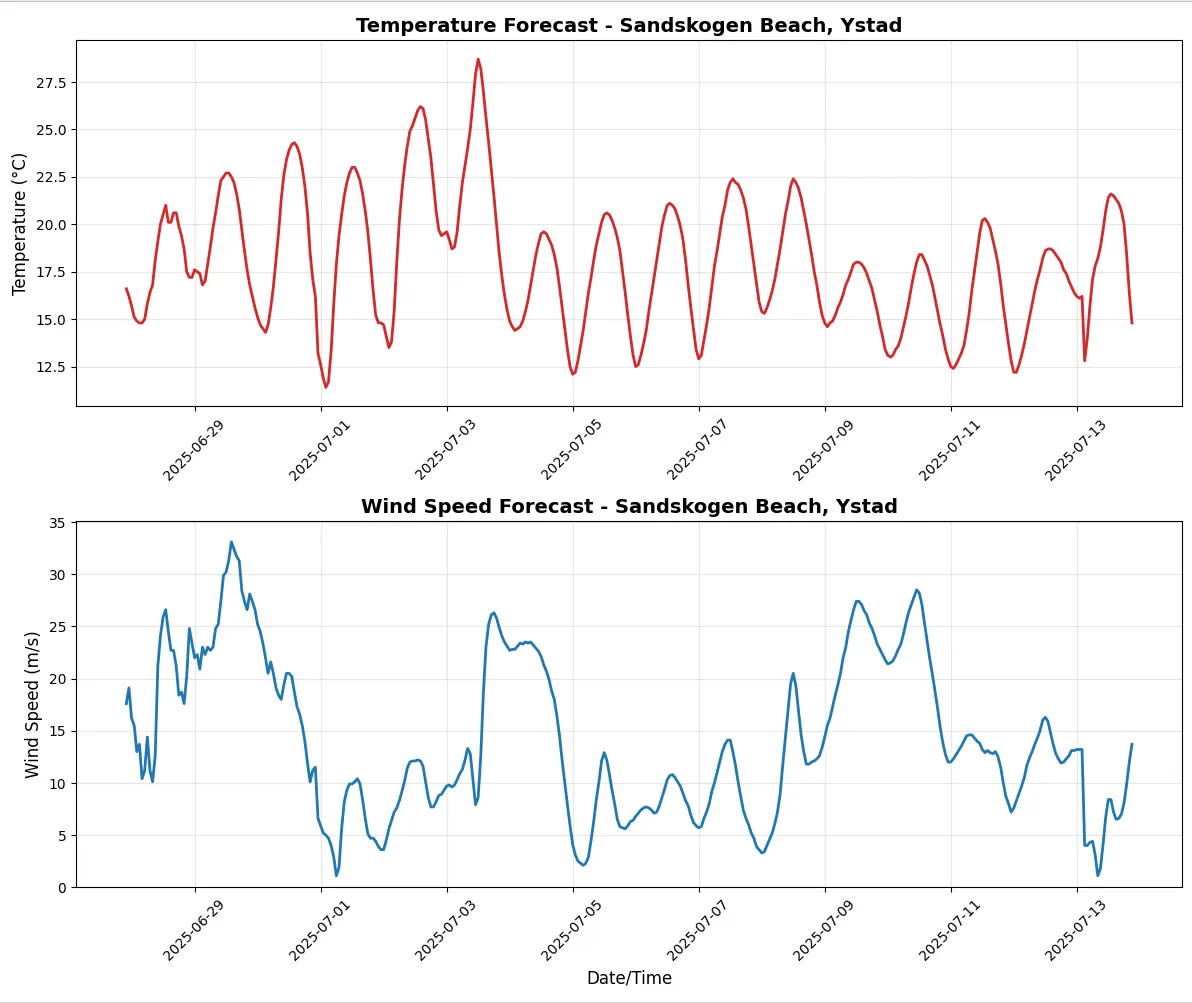
According to the analysis above, the best day in the next couple of weeks is next Tuesday, but unfortunately it is not the weekend :unamused:

But is it going to rain? To answer this question we fetch some additional data from MET Norway's THREADS server
print("Downloading precipitation data...")
response = requests.get(url, params=params)
if response.status_code == 200:
precip_data = response.json()
hourly_precip = precip_data['hourly']
precip_times = hourly_precip['time']
precipitation = hourly_precip['precipitation']
# Create precipitation dataframe
df_precip = pd.DataFrame({
'datetime': pd.to_datetime(precip_times),
'precipitation': precipitation
})
print("✓ Precipitation data downloaded successfully")
# Merge with nice weather data
nice_with_precip = pd.merge(nice, df_precip, on='datetime', how='left')
print(f"\nNice weather forecast with precipitation:")
print("=" * 80)
print("Date/Time | Temp | Wind | Rain | Day Type | Weather Quality")
print("=" * 80)
best_times = []
for idx, row in nice_with_precip.iterrows():
weekend_str = "Weekend" if row['is_weekend'] else "Weekday"
rain_str = f"{row['precipitation']:.1f}mm" if row['precipitation'] > 0 else "No rain"
# Determine weather quality
if row['precipitation'] == 0 and row['YR_det_temp'] >= 25:
quality = "EXCELLENT ⭐⭐⭐"
best_times.append(row)
elif row['precipitation'] == 0 and row['YR_det_temp'] >= 22:
quality = "VERY GOOD ⭐⭐"
best_times.append(row)
elif row['precipitation'] == 0:
quality = "GOOD ⭐"
elif row['precipitation'] <= 0.5:
quality = "Fair (light rain)"
else:
quality = "Poor (rain)"
print(f"{row['datetime'].strftime('%Y-%m-%d %H:%M')} | {row['YR_det_temp']:4.1f}°C | {row['YR_det_wind']:4.1f}m/s | {rain_str:8} | {weekend_str:7} | {quality}")
print("\n🌟 BEST TIMES FOR BEACH WEATHER:")
if best_times:
for row in best_times:
weekend_str = "Weekend" if row['is_weekend'] else "Weekday"
print(f" • {row['datetime'].strftime('%A, %B %d at %H:%M')} - {row['YR_det_temp']:.1f}°C, {row['YR_det_wind']:.1f}m/s, no rain ({weekend_str})")
else:
print("No excellent weather periods found in the forecast")
else:
print(f"Error downloading precipitation data: {response.status_code}")
According to this, Tuesday will indeed be a nice time for going to the beach.

In order to decide if this is indeed a good prediction we will have to wait a few days to:
- Reach Tuesday
- Get hold of some observation data to compare with the predictions
Note that I fetched the data around 15:30 today, so the numbers might vary as one approaches the date in question. Additionally, I am pulling out the post-processed product from the API. I will evaluate the predictions from this post during the next week using one of verification packages I use at work.